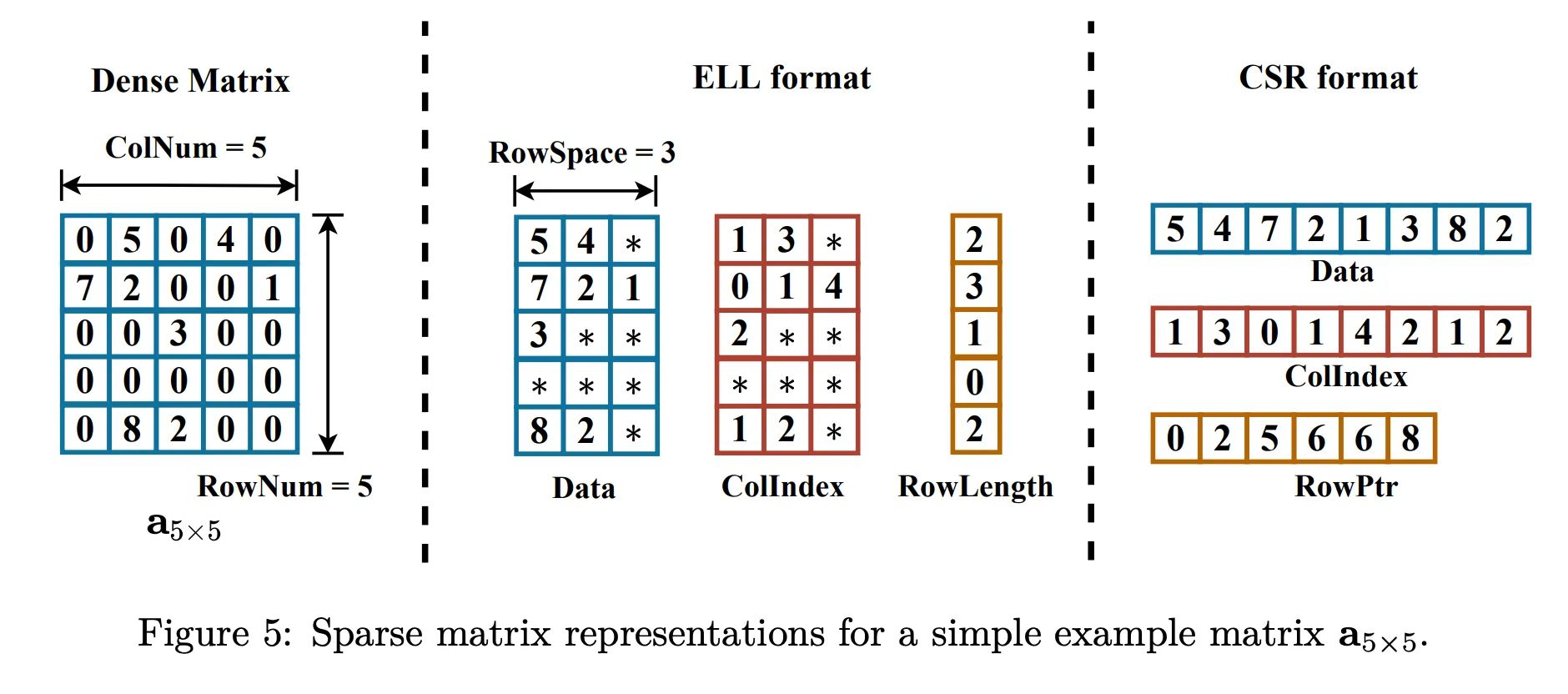
| Array | Description |
|---|---|
values | Non-zero values in each row; padded with zeros if needed |
col_indices | Column indices of the values; dummy indices used for padding |
row_length | Actual number of non-zero elements in each row |
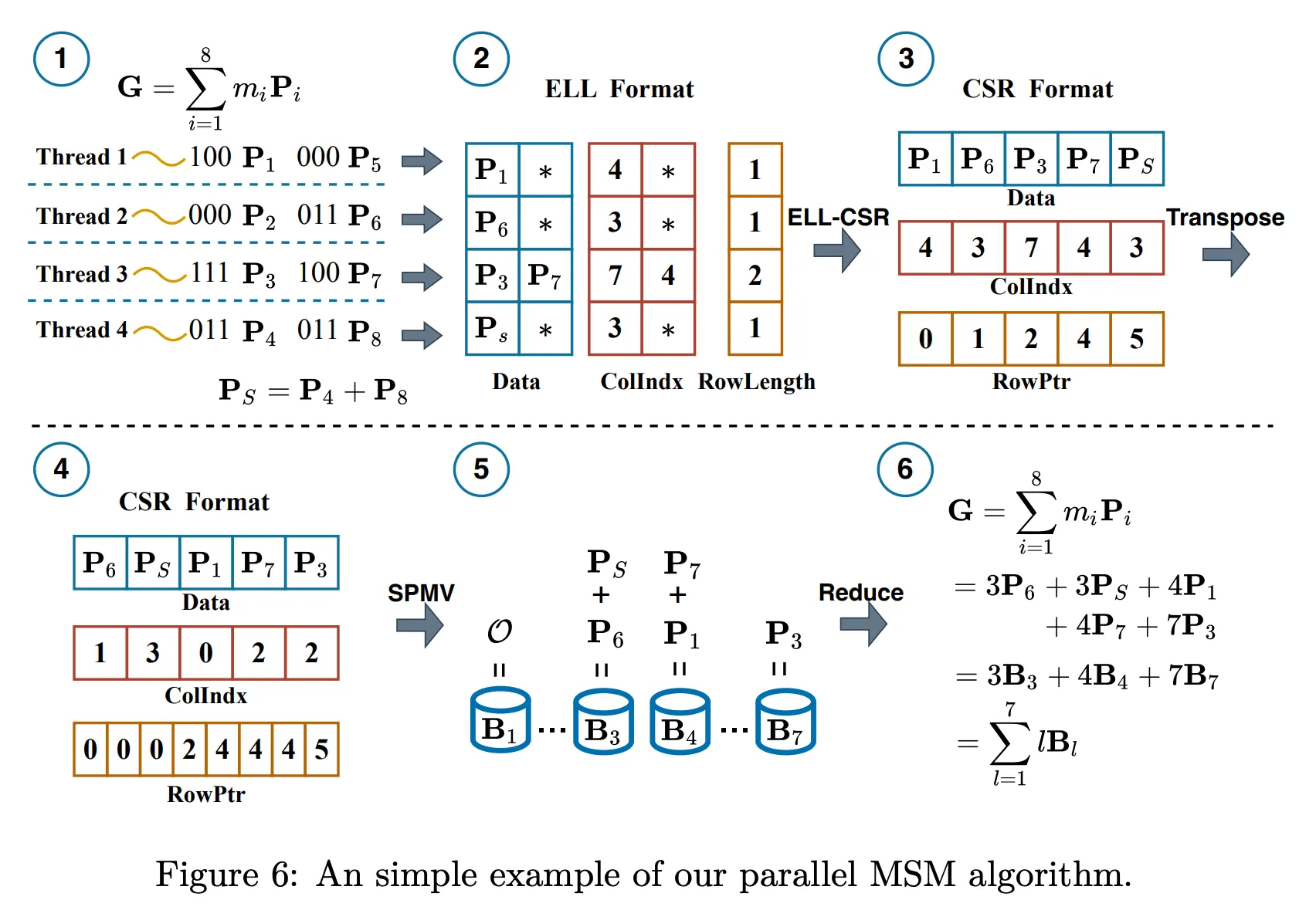
| Step | Description |
|---|---|
| ① Sort rows | By row length (ascending) |
| ② Group rows | Rows are grouped so that each group has a similar workload, ensuring balanced warp-level execution. |
| ③ Warp scheduling | One warp handles one group (ensures uniform workload) |
| ④ Warp allocation | Warp count is proportional to the number of non-zeros in each group |

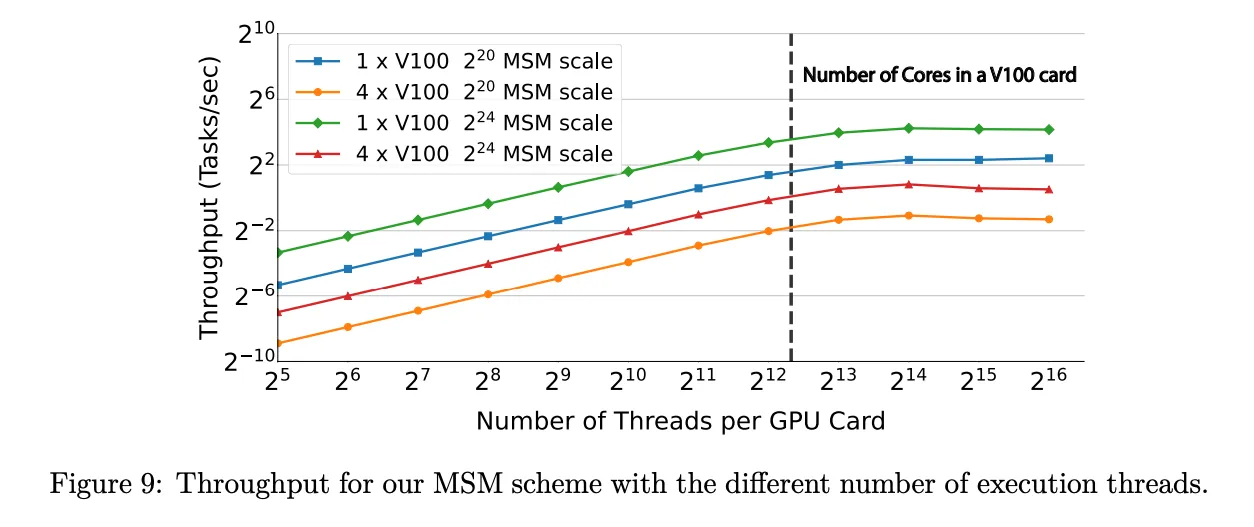
| Scheme | Description | Limitation |
|---|---|---|
| CSR-Scalar [Gar08] | Each thread handles one row | Severe load imbalance when row lengths vary significantly |
| CSR-Vector [BG09] | A row is divided across multiple threads | Only effective in specific scenarios |
| CSR-Balanced | Balances load based on row distribution | Requires row sorting, which increases complexity |
| Module | Description |
|---|---|
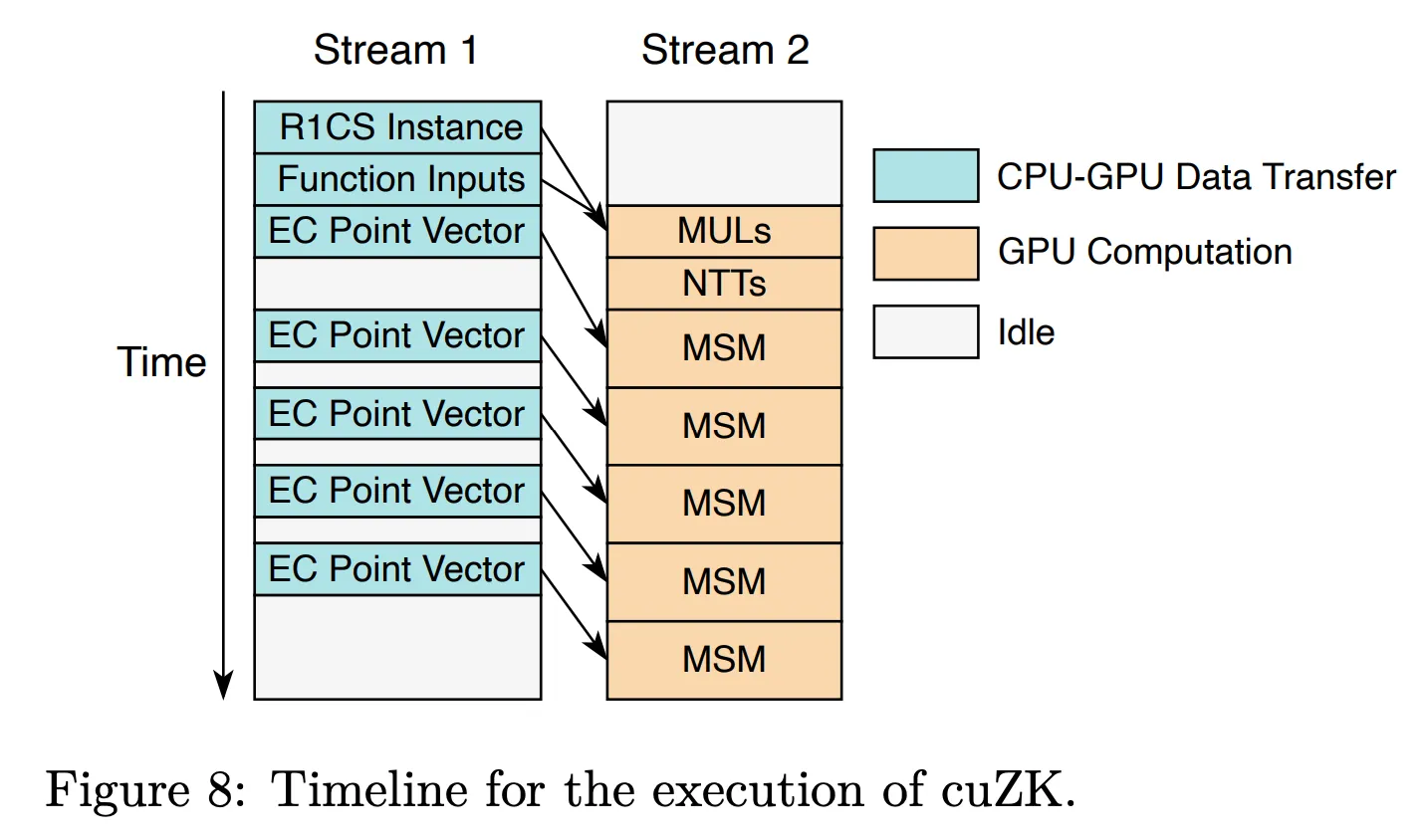
| R1CS instance | Three CSR matrices generated from the circuit |
| Function inputs | Input vector including intermediate computation results |
| Prover key | Large structure composed of elliptic curve (EC) point vectors |